发布日期:2024-12-24 06:02 点击次数:137

从今日全国石榴(大籽石榴)批发市场价格上来看正规配资网排名,当日最高报价16.00元/公斤,最低报价15.20元/公斤,相差0.80元/公斤。
从今日全国石榴批发市场价格上来看,当日最高报价16.00元/公斤,最低报价3.00元/公斤,相差13.00元/公斤。
所有模型在多轮对话中表现显著衰减。点击收听本新闻听新闻
在大语言模型(LLMs)不断发展的背景下,如何评估这些模型在多轮对话和多语言环境下的指令遵循(instruction following)能力,成为一个重要的研究方向。
现有评估基准多集中于单轮对话和单语言任务,难以揭示复杂场景中的模型表现。
最近,Meta GenAI团队发布了一个全新基准Multi-IF,专门用于评估LLM在多轮对话和多语言指令遵循(instruction following)中的表现,包含了4501个三轮对话的多语言指令任务,覆盖英语、中文、法语、俄语等八种语言,以全面测试模型在多轮、跨语言场景下的指令执行能力。

论文链接:https://arxiv.org/abs/2410.15553
Multi-IF下载链接:https://huggingface.co/datasets/facebook/Multi-IF
实验结果表明,多数LLM在多轮对话中表现出显著的性能衰减。
例如,表现最佳的o1-preview模型在第一轮指令的平均准确率为87.7%,但到第三轮下降至70.7%
此外,非拉丁文字语言(如印地语、俄语和中文)的错误率明显更高,反映出模型在多语言任务中的局限性。这些发现展示了当前LLM在处理复杂多轮和多语言指令任务上的挑战和改进空间。
Multi-IF的发布为研究人员提供了更具挑战性的评估基准,有望推动LLM在全球化、多语言应用中的发展。
数据集构建
Multi-IF数据集的构建过程经过了多轮精细的设计和筛选,既有模型也有人类专家的参与。
多轮扩展
首先,研究团队基于已有的单轮指令遵循数据集IFEval,将每个单轮指令扩展为多轮指令序列。通过随机采样和模型生成,研究团队为每个初始指令增加了两轮新指令,形成一个完整的三轮对话场景。
首先随机采样一个指令类型(Intruction Type)比如「字数限制」、「限制输出格式为列表」、「添加特定关键短语」等等,然后将之前的指令和这个指令类型提供给语言模型,让它生成一个符合上下文的指令,比如「旅行计划不超过400词」;随机采样可能导致指令之间存在冲突。
为了确保多轮指令的逻辑一致性和层次递进性,研究团队设计了一套两步冲突过滤机制:
1. 模型过滤:使用Llama 3.1 405B模型自动检测可能存在矛盾的指令组合。例如,如果第一轮要求生成详细描述,而第二轮要求简洁总结,这种冲突指令会被筛选出来。
2. 人工审核:在初步过滤后,团队通过人工标注对指令进行细化和调整,以确保每一轮指令既具有挑战性又保持逻辑连贯。
多语言扩展
为了提高数据集的多语言适用性,研究团队采用了以下方法将数据集从英文扩展至多语言版本:
1. 自动翻译:使用Llama 3.1 405B模型将原始英语指令翻译为中文、法语、俄语、印地语、西班牙语、意大利语和葡萄牙语七种语言。
2. 人工校对:翻译结果经过语言专家的人工审校,以确保在语义和语法上贴合各语言的自然使用习惯,同时消除因翻译可能带来的歧义或误导。
这一多轮扩展和多语言适配的构建流程,使Multi-IF成为全面评估LLM指令遵循能力的强大工具。
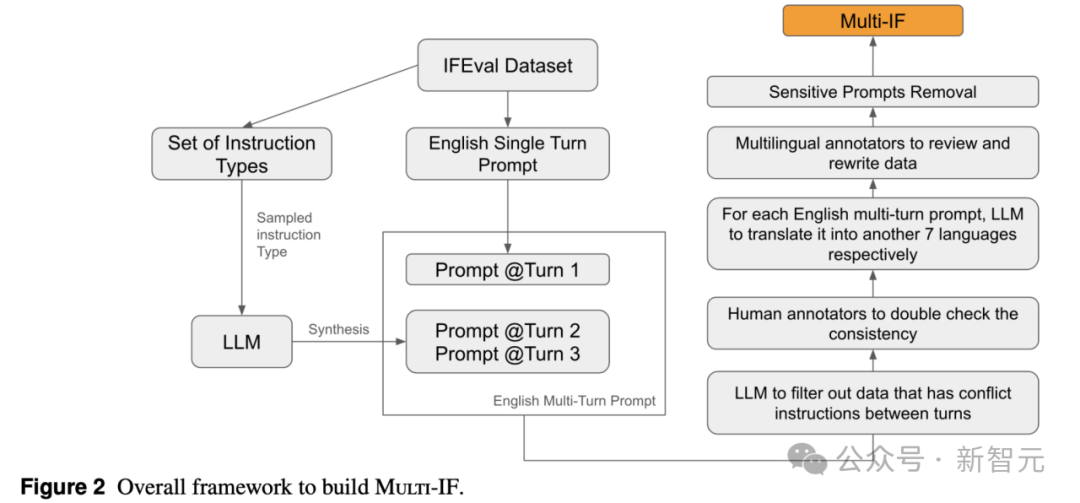
总体实验结果
在Multi-IF基准上,Meta团队对14种最先进的大语言模型(LLMs)进行了评估,涵盖了OpenAI的o1-preview、o1-mini,GPT-4o,Llama 3.1(8B、70B和405B),Gemini 1.5系列,Claude 3系列,Qwen-2.5 72B,以及Mistral Large等。
实验显示,整体上o1-preview和Llama 3.1 405B表现最佳,在平均准确率上领先其他模型。特别是在多轮指令任务中,o1-preview和Llama 3.1 405B模型在三轮指令的平均准确率分别为78.9%和78.1%,展现了较高的指令遵循能力。
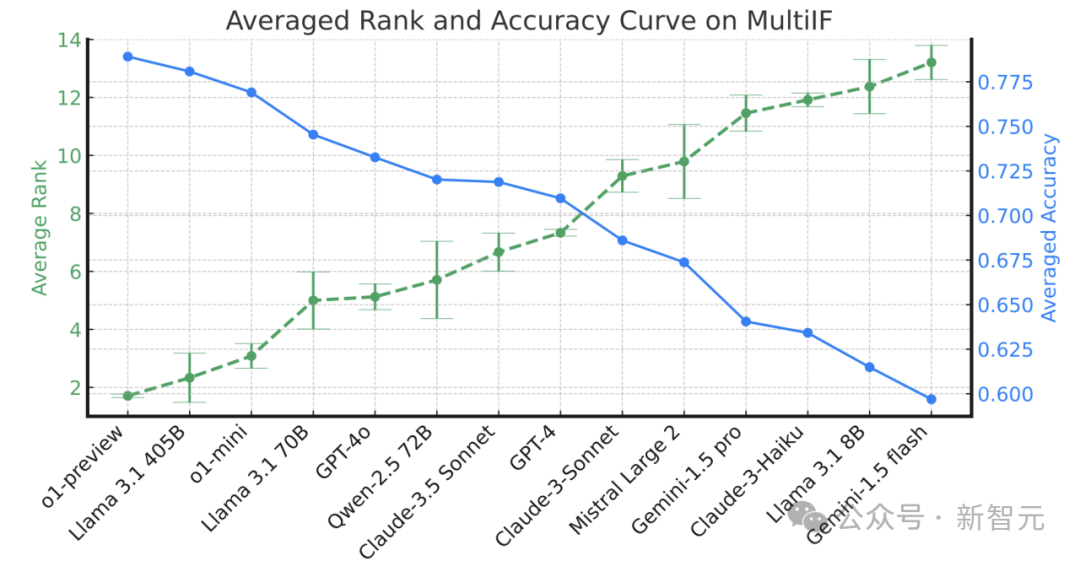
多轮对话中的指令遵循
实验表明,所有模型在多轮对话中的指令遵循准确率随着轮次增加而显著下降。这种下降在某些模型中尤为明显,如Qwen-2.5 72B在第一轮准确率较高,但在后续轮次中的表现迅速下滑。
相比之下,o1-preview和Llama 3.1 405B在多轮任务中的准确率相对稳定,展现出较强的持续指令遵循能力。总体而言,这些结果说明,多轮对话对当前LLM构成了较大挑战,模型在多轮次中遵循指令的能力有待提高。
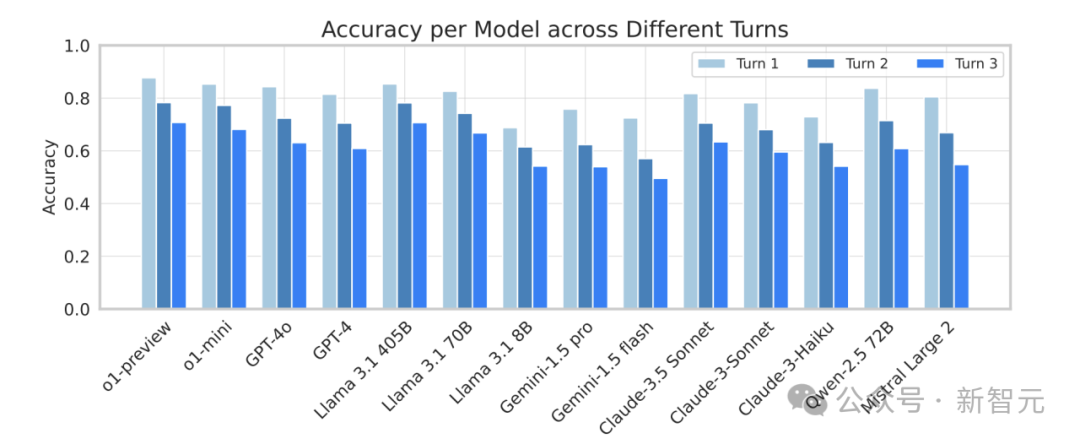
多轮对话中的指令遗忘
在多轮对话中,模型往往出现「指令遗忘」现象,即在后续轮次中未能遵循前一轮成功执行的指令,研究团队引入了「指令遗忘率」(Instruction Forgetting Ratio, IFR)来量化这种现象。
IFR值表明,高性能模型如o1-preview和Llama 3.1 405B在多轮对话中的遗忘率相对较低,而有些模型比如Gemini在IFR值上明显偏高,表现出较高的指令遗忘倾向。
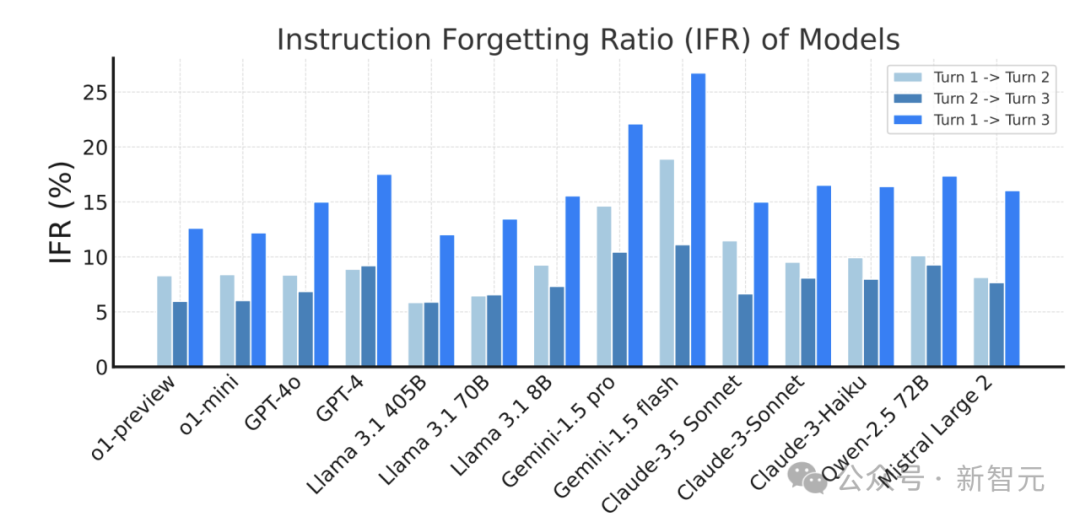
此外,对于Llama 3.1系列模型,随着模型规模从8B扩展到405B,其指令遗忘率(即IFR)逐渐降低。这表明,增大模型规模可以有效提升其在多轮对话中保持指令一致性的能力。
多轮对话中的自我纠正
模型在多轮任务中是否能够纠正之前的错误也是一个重要的性能衡量标准,实验通过计算「错误自我修正率」(Error Correction Ratio, ECR)来评估这一能力。
结果显示,o1-preview和o1-mini在错误自我修正方面表现突出,能够在后续轮次中纠正约25%的之前未遵循的指令。这些模型似乎能够利用某种“反思”能力来提高指令执行的水平。
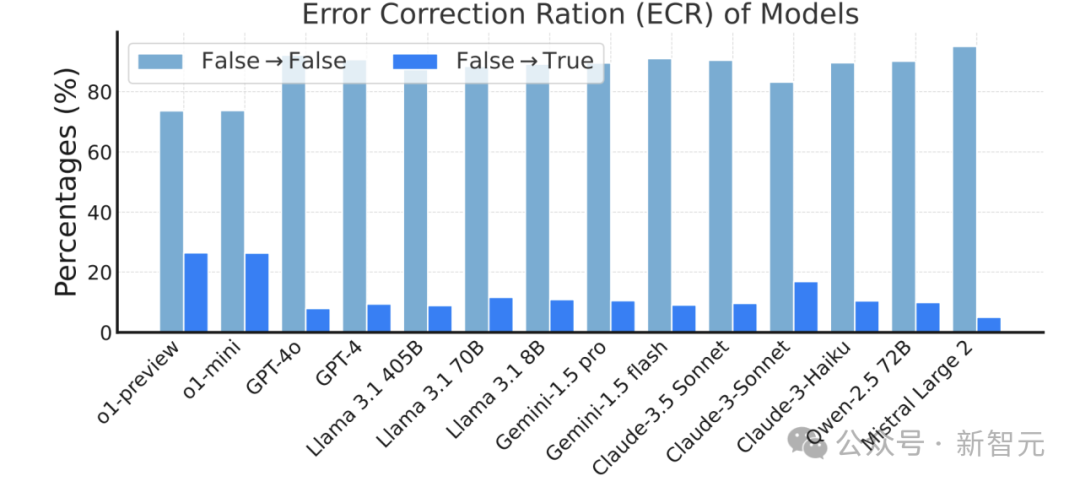
相比之下,其他模型在自我修正方面表现一般,这一结果表明,具备反思能力的模型在多轮任务中能够更好地处理错误并提升指令遵循的稳定性。
多语言指令遵循
在多语言环境下,模型的指令遵循能力表现出显著的语言差异。实验显示,英语的指令执行准确率普遍最高,尤其是在Llama 3.1 405B模型上,英语准确率接近0.85。法语和意大利语的表现也较为接近英语,而俄语、印地语和中文等非拉丁文字的准确率则明显较低。
例如,o1-preview模型在俄语和印地语中的准确率低于其在英语、法语等语言中的表现。总体而言,非拉丁文字语言的错误率高于拉丁文字语言,这在多语言指令任务中尤为突出。
实验结果还表明,不同模型在多语言指令遵循中的表现存在一定差异。o1-preview在所有语言中的表现相对稳定,并在中文、西班牙语、意大利语和印地语中稍胜Llama 3.1 405B,而GPT-4o的表现则略逊于前两者。
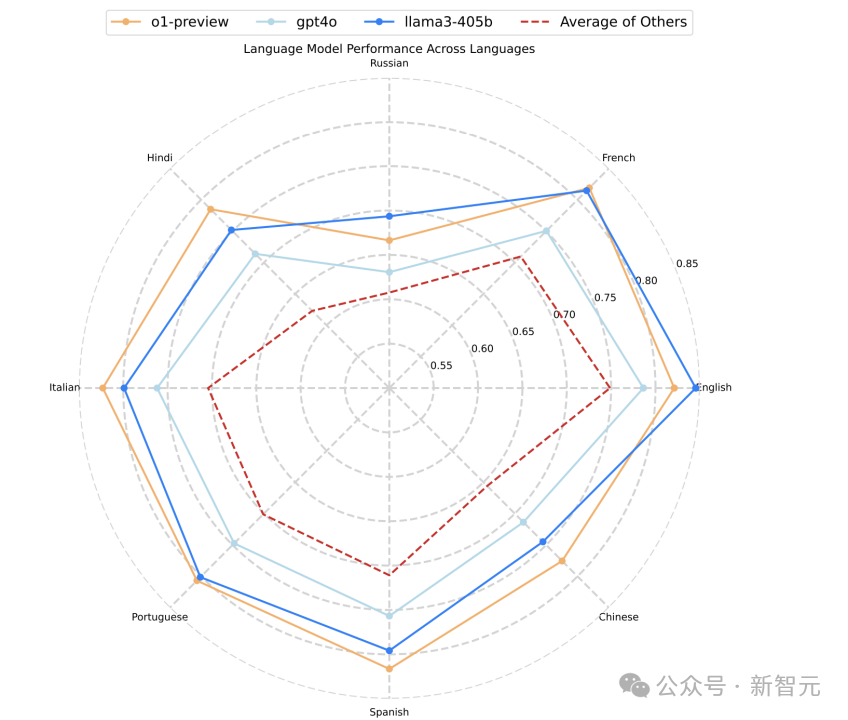
平均而言,非拉丁文字的语言往往会出现更高的指令遵循错误,表明当前模型在多语言环境,尤其是对非拉丁文字的支持方面,仍有提升空间。
这些结果反映出,尽管现有的先进LLM在多语言任务上已经展现出一定的能力,但在处理俄语、印地语和中文等非拉丁文字语言的指令遵循任务时仍存在明显的局限性。这也为未来多语言模型的改进指出了明确的方向。
结论
综上所述,Multi-IF基准通过多轮对话和多语言环境的复杂指令任务,揭示了当前大语言模型在指令遵循能力上的不足之处。
实验结果表明,多数模型在多轮任务中存在准确率下降和指令遗忘的问题,且在非拉丁文字的多语言任务中表现较差。Multi-IF为进一步提升LLM的多轮对话和跨语言指令遵循能力提供了重要的参考。
作者介绍

通讯作者Yun He(贺赟)是Meta GenAI团队的一名研究科学家,博士毕业于Texas A&M University,专注于大语言模型Post-training的研究和应用。
他的主要研究方向包括指令跟随(instruction following)、推理能力(Reasoning)以及工具使用(tool usage),旨在推动大语音模型在复杂多轮对话中的表现。

共同一作金帝是Meta GenAI Senior Research Scientist,负责Meta AI Agentic Code Execution和Data Analysis方向,博士毕业于MIT。
主要研究方向为大模型后训练对齐(RLHF,Alignment)正规配资网排名,模型推(Model Reasoning),和大模型智能体(Agent)方向。
上一篇:北京股票配资网 她是常熟出名的美丽女模特,因贪慕虚荣4年借款14亿,为躲债整容
下一篇:股票交易的平台 怀孕了,化妆品还能用吗?这份安全清单让你放心选择!